
Guest Post written by Sidney Feiner, Start.io’s Data Platform Team
Here at Start.io, we handle millions of events per second from our SDK, implemented in many applications both on Android and iOS. To successfully handle and store all those events, we develop scalable applications (previously Spark, currently Flink) that are very focused on performance.
Then, our favorite people over at Data take the data ingested by our databases and perform their ETLs.
Once the data is done, we develop APIs that access this data in the most efficient way and return the results to whomever needs them.
Some of those APIs have a very high throughput (thousands of requests per second) and require quick responses (5-20 ms!), so in order to support those requirements, we must implement efficient caching. And that’s what we are going to explore in this blog post – how we did it and how you can too. I hope it’s helpful!
Motivation
To improve query performance and also decrease storage size, we want to avoid a string in every record. Instead, we store a lookup value (int) for every string, and save that key’s original string value in a separate table. This is also very useful in instances of columns with repeating values, such as countries, cities, etc.
That lookup key is generated during ingestion (getOrCreate), and it’s important that when our APIs query the data, they return the original string values.
In both stages (ingestion and APIs), it would be useful to have a cache for the lookups, in order to avoid querying the database each and every time.
Some APIs require querying multiple tables and data sources concurrently. Those APIs are implemented in Scala (Play framework), but lately we’ve been thinking of reproducing them in Golang. So, the first thing we need to do is find a caching library that best fits our use-case.
Use-case
Generally, our use-case is as follows:
- During ingestion, we check the local cache (cache read) for every value we need to use a lookup for (value to key).
- If it exists, return the value.
- If it doesn’t, query the database table that holds all the lookups.
- If it exists in the database, save its value inside the cache (cache write) and return it.
- If it doesn’t:
- Generate a key for it.
- Insert into database.
- Return the key.
- When the Data API queries data (key to value), we first read the local cache (cache read).
- If it exists, return the key.
- If it doesn’t, query the database table that holds all the lookups.
- If it exists, save the value-to-key mapping inside the cache (cache write) and return it.
- If it doesn’t, return null.
And to allow all those at scale, we actually need a cache that has good “cache-read” benchmarks when read with high concurrency.
Golang caches included
For those benchmarks, we conducted benchmark tests on some Golang caching libraries that had a commit in the last year:
- Saves data in heap but isn’t collected by GC
- Allows enforcing a maximum size for a single entry
- Described as “nearly LRU” (Least Recently Used eviction)
- Maximum allowed memory must be pre-allocated
- Newest of the bunch so it’s usable but still under active development
- Developed by DGraph, which wasn’t content with the performance of the existing cache libraries. DGraph’s main requirements were:
- Concurrent cache that scales well as number of cores and go-routines increase
- High cache-hit ratio
groupcache was considered but left out because it has some IO overhead and, in our case, we don’t need a distributed cache.
Benchmarking
Now that we use Golang, we have the power of go-routines. So we can change the “key retrieval” process by concurrently querying the cache and the database, instead of first querying the cache and only then querying the database if needed.
The benchmarking process consisted of a few steps:
- Without concurrent actions on cache and retrieving keys in random order.
- With concurrent actions on cache and changing cache sizes, simulating real-life pipeline values (cache read and write).
- With concurrent actions on cache and changing cache sizes. Populate cache at first and then test only cache reads.
First Step – No concurrency, random keys
For the first step, we conducted the benchmarking with no concurrency, and with generating a sequence of values we want to retrieve from the cache. (Remember: “retrieving” a value from the cache means that we try fetching it from the cache and if it doesn’t exist, we retrieve it from the database and insert it into the cache).
When generating keys for the benchmarks, we split the results into 3 “sub-tests” with the following expected hit rates:
- 20%
- 50%
- 80%
As the expected hit rate goes up, we obviously expect a shorter read time, because there is no reason to wait for the database’s response as the item should already be in the cache.
For every expected hit rate, we generated a sequence of lookups keys. This sequence was applied on every cache in the same order to ensure fairness for all caches. The sequence was generated in the following way:
- Find keys that definitely DON’T exist in lookup table (keys to be used when we want the longest possible time for a read).
- Find keys that definitely DO exist in lookup table (keys to be used when we want a miss for the first time and then only hits).
- Generate over 2 million values and based on hit probability:
- If we need a miss, we either query a key that doesn’t exist in the table or query a key that does and will then be saved in cache (50/50 for those cases).
- If we need a hit, we query a key that exists in table AND that we queried before, and therefore it should be in cache.
Once the sequence is generated, we exhaust the whole sequence on a single cache, for every cache. For every retrieval, we log the amount of time the retrieval took, whether we got a hit, and if we got a hit – if it was a local hit (found in cache) or not (retrieved from database).
Results
Writes
The following graph shows the average time of retrieving a key’s value from the database and inserting it in the cache. Note that the write times do not only reflect the time it took to write a new entry into the cache, but also include the key retrieval from the database.
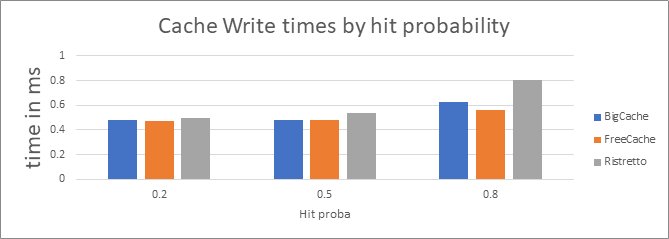
Because we’re looking at the average write time, and all caches queried the same values from the database, we can still deduct that FreeCache has the advantage here.
Reads
The following graph shows the average read time of a key when it was already in the cache, per hit rate. The difference between the hit rates could indicate a difference in performance when the cache gets fuller.
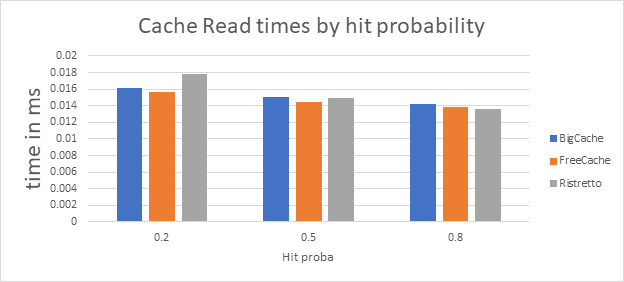
It seems that FreeCache is the more stable, but Ristretto has better read times (when we have more reads, Ristretto shows better results).
Overall times
The following graph shows the overall average time of retrieving keys, whether it was found locally in the cache or the database.
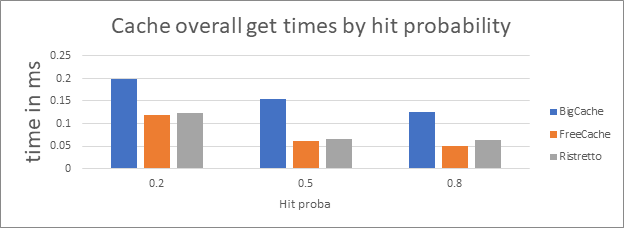
To sum up, it appears that FreeCache is the clear winner.
Conclusions
When we query randomly without concurrency, FreeCache is the clear winner.
Now would be the time to guess whether this trend will continue, because who doesn’t like a good guessing game?
Second Step – With concurrency and different cache sizes
For this step, we actually wanted to drill a bit deeper:
- Analyze the cache’s performance when it has different sizes.
- Instead of randomly simulating keys, see how the cache behaves when we use a real-life sequence of values.
To implement the second bullet, a million events were fetched from our historic data, ordered according to their ingestion time. This ensures we simulate a real-life sequence of events and, consequently, real life hit rates.
Benchmarks results were split into the following concurrencies:
- 8
- 16
- 32
- 64
The configured concurrency defined the number of go-routines to be created in order to retrieve keys from the cache, thus creating opportunities for concurrently reading and/or writing from the cache.
Results
Writes
The following graph shows the average time of writing a value into the cache, per concurrency.
In this instance, we measured times, excluding the querying time from the DB, so these measured times represent only the net writing time to the cache.
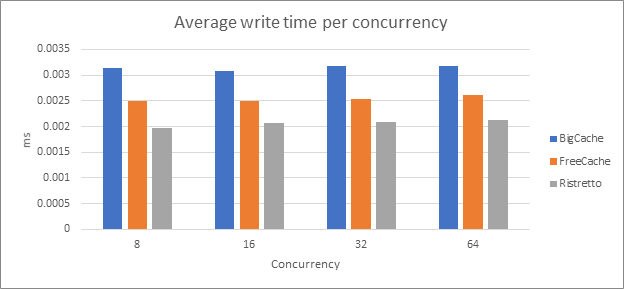
Ristretto wins this round.
Reads
The following graph shows the average read time of a key when it was already in the cache, per concurrency.
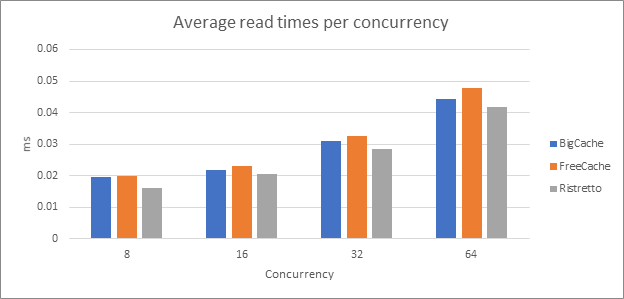
Again, the winner is Ristretto.
Did you bet on FreeCache before? Because now you’re probably starting to regret it.
Overall times
The following graph shows the overall average time of retrieving keys, whether it was found locally in the cache or the database.
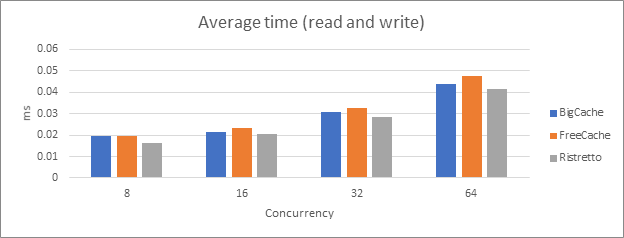
It seems that Ristretto is the clear winner here.
Hit rates
The following graph shows the difference in hit rates with an additional drill down into the cache maximum size in MB.
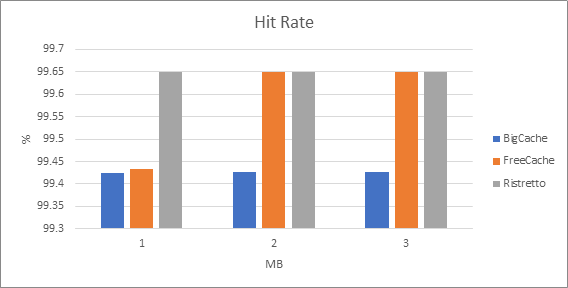
Here, it is clear that we had a very high hit rate, just as expected. But, more interesting is when the cache had the smallest size limit, FreeCache had a slightly smaller hit rate than Ristretto.
Number of items in cache
After the previous results, my interest was piqued, and I wondered how many items the cache could hold. For every cache size, the following graph shows the number of items in cache as the program progressed.
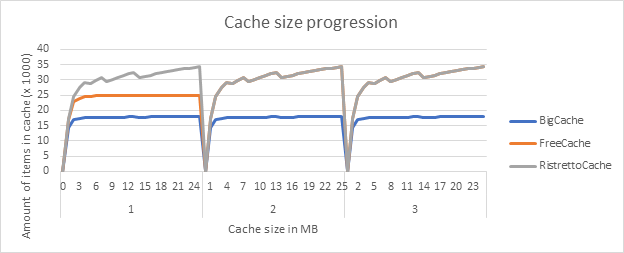
It appears that 2 and 3MB were more than enough, so FreeCache and Ristretto could both hold the same number of items. But even more interesting is that when the cache’s size was bound by 1MB, Ristretto was able to hold more items, which explains the higher hit rate when the cache size was only 1MB.
Disclaimers:
- I’m not sure how it’s possible that Ristretto and FreeCache held exactly the same number of items all the time, as they probably use different eviction techniques.
- Events that were originally fetched do not contain distinct values, so it’s normal that we had less than a million items in the cache.
- I did not count the amount of distinct values to know the final percentage of items we held in the cache.
Read times vs cache size
The following graph shows the read times for each cache size, as it grows.
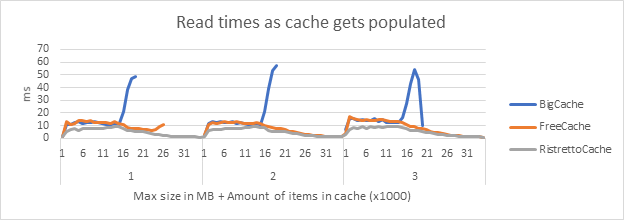
From this, we can easily conclude that Ristretto always has better read times than FreeCache. We can also see that when FreeCache is fully populated, its read times increase.
Notes:
- For all cache sizes, BigCache stops before the other caches because it doesn’t reach the same number of entries.
- In cache size 2 and 3MB, we see only Ristretto at the tail, but FreeCache and Ristretto are almost identical and therefore their lines overlap.
Conclusion
When we look at low concurrency apps, FreeCache might be slightly better. But as we scale our app, Ristretto will probably be the better option.
For any of you that crossed your fingers for FreeCache, you have my sympathies!
Third Step – Cache exhaustion
In this step, we wanted to assume that most actions will be reads from the cache by preloading the cache with values (this happens in some of our APIs anyway) and read from it with very high concurrencies.
The cache was populated in the following way:
- 5,000,000 keys and their values were queried from the database.
- For every cache size (1-61 with intervals of 10), we created caches with the corresponding size and populated it with ALL the values we queried.
- We “exhausted” (read every single key that was queried) the cache by concurrency. For every concurrency:
- Shuffle the queried keys:
- Done once per concurrency, meaning the caches are queried with the same values in the same order.
- For every cache we configured, query the keys in the same order.
- Divide the shuffled data in batches where each batch is the same size as the concurrency.
- For every such batch, concurrently get all its values from the cache using go-routines.
- Shuffle the queried keys:
For example:
- We create 3 caches of size 51MB:
- The 3 caches are Ristretto, FreeCache, and BigCache.
- We shuffle the 5,000,000 keys.
- For every cache:
- If current concurrency is 1,000, we group the shuffled keys in batches of 1,000.
- Run 1,000 concurrent reads on the cache.
- Wait until 1,000 concurrent reads finish.
- Finish when all keys were read from cache.
Remember that we already saw that when the cache is big enough, Ristretto wins with reading times, so we tested cache sizes when data wouldn’t completely fit in.
Fifty million records from the table we queried should be around 220-250MB, and we used caches up until 51MB.
Results
Reads
The following graph shows the average read time of a key when it was already in the cache, per concurrency.
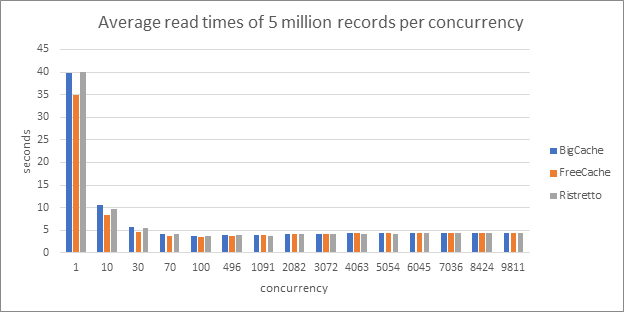
As we noticed in the previous tests, for lower concurrencies, FreeCache is better, but for higher concurrencies, Ristretto wins.
Hit rates
The following graph shows the increase in hit rate as the cache size increases.
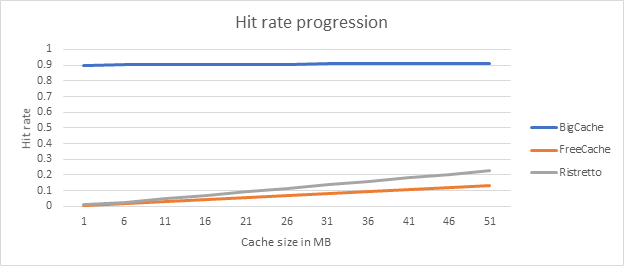
There is a linear increase for Ristretto and FreeCache, which makes sense. Note that as we’ve already seen for the same size, Ristretto has a better hit rate than FreeCache.
The reason BigCache has such a high hit rate is because it failed limiting the cache size (as seen in the following graph).
As mentioned, all the data was around 200-250MB, so it makes sense that when the cache is at 50MB, we have a hit change of around 22% (with Ristretto), which is better than FreeCache’s 13.6%.
Number of items in cache
The following chart shows the number of items in cache as the program progresses, per cache size.
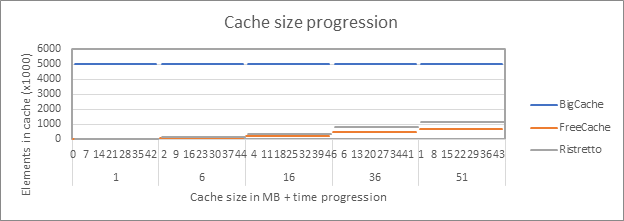
These results make sense, because cache is populated during initialization. And as expected, Ristretto has more items in its cache than FreeCache.
Conclusion
Final verdict? When dealing with high concurrency apps, Ristretto is the winner, with better hit rates and read times.
If you’re not using concurrency, FreeCache might be a better option for you, but on the other hand? You might as well just use Python.


